
This is Part A — Handling BeautifulSoup and avoiding blocks.
Make sure to check out Part B and Part C of this Web Scraping series.
What is web scraping and when would you want to use it?
- The act of going through web pages and extracting selected text or images.
- An excellent tool for getting new data or enriching your current data.
- Usually the first step of a data science project which requires a lot of data.
- An alternative to API calls for data retrieval. Meaning, if you don’t have an API or if it’s limited in some way.
For example:
Tracking and predicting the stock market’s prices by enriching the up to date stock prices with the latest news stories. These news stories may not be available from an API and therefore would need to be scraped from a news website. This is done by going through a web page and extracting text (or images) of interest.
Our web scraping project was part of the Data Science fellows program at ITC (Israel Tech Challenge) which was designed to expose us to the real world problems a data scientist faces as well as to improve our coding skills.
In this post, we show our main steps and challenges along the way. We have included code snippets and recommendations on how to create an end to end pipeline for web scraping. The code snippets we show here are not OOP (Object Oriented Programming) for the sake of simplicity, but we highly recommend to write OOP code in your web scraper implementation.
Main tools we used:
- Python (3.5)
- BeautifulSoup library for handling the text extraction from the web page’s source code (HTML and CSS)
- requests library for handling the interaction with the web page (Using HTTP requests)
- MySQL database — for storing our data (mysql.connector is the MySQL API for Python)
- API calls — for enriching our data
- Proxy header rotations — generating random headers and getting free proxy IPs in order to avoid IP blocks
Workflow
The website
In this project we were free to choose any website. The websites chosen by the rest of the cohort ranged from e-commerce to news websites showing the different applications of web scraping.
We chose a website for scientific articles because we thought it would be interesting to see what kind of data we could obtain and furthermore what insights we could gather as a result of this data.
We have chosen to keep the website anonymous. In any case the goal of this post is to outline how to build a pipeline for any website of interest.
Scraping Scraping Scraping
BeautifulSoup
First, one must inspect the website in order to determine which data one would like to scrape. It involves a basic understanding of the websites structure so that your code can scrape the data you want.
In order to inspect the structure of the website, open the inspector of the web page, right click on the page → hit “Inspect element”.
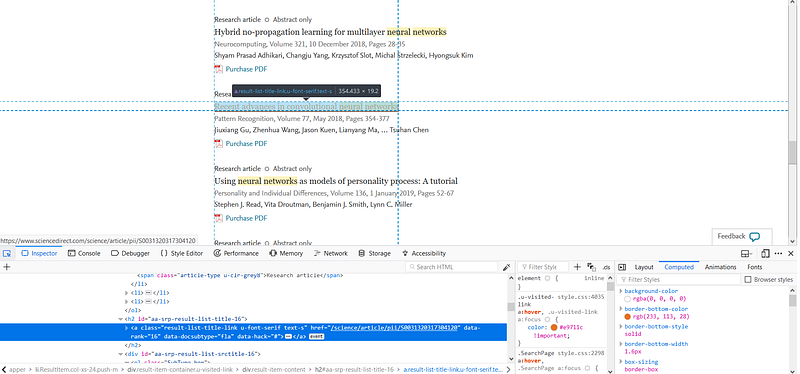
Then, locate the data you want to scrape and click on it. The highlighted part in the inspector pane shows the underlying HTML text of the webpage section of interest. The CSS class of the element is what BeautifulSoup will use to extract the data from the html.
In the following screenshot one can see that the “keywords” section is what needs to be scraped. Using the inspector, one can locate the HTML element of the “keywords” section and its CSS class.
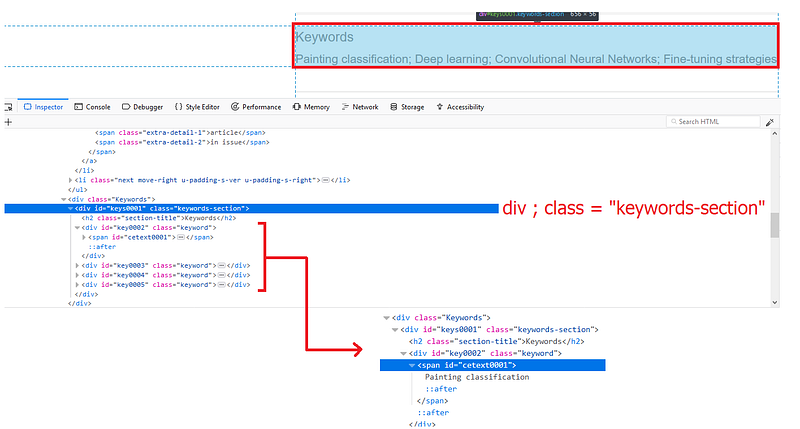
The structure is as follows:
div (class=”keywords-section”) → div (class=“keyword”).
Using beautiful soup, the code to get all keywords is as follows:
From here, it’s pretty much the same. Locate the desired section, inspect the HTML element and get the data. Full documentation and much more examples of beautifulsoup can be found here (very friendly).
The scraping process involves many HTTP GET requests in a short amount of time because in many cases one may need to navigate automatically between multiple pages in order to get the data. Moreover, having an awesome scraper is not just about getting the data one wants, it’s also about getting new data or updating existing data frequently — This might lead to being blocked by the website. This leads us to the next section:
How to avoid blocks?

In general, websites don’t like bot scrapers but they probably don’t prevent it completely because of the search engine bots that scrape websites in order to categorize them. There’s a robots exclusion standard that defines the website’s terms and conditions with bot crawlers, which is usually found in the robots.txt file of the website. For example, the robots.txt file of Wikipedia can be found here: https://en.wikipedia.org/robots.txt.
The first few lines of Wikipedia’s robots.txt:
# robots.txt for http://www.wikipedia.org/ and friends # # Please note: There are a lot of pages on this site, and there are # some misbehaved spiders out there that go _way_ too fast. If you're # irresponsible, your access to the site may be blocked.
As you can see, Wikipedia’s restrictions are not too strict. However, some websites are very strict and do not allow crawling part of the website or all of it. Their robots.txt would include this:
User-agent: * Disallow: /
How to deal with blocks?
One way of doing this is by rotating through different proxies and user agents (headers) when making requests to the website. Also, it is important to be considerate in how often you make requests to the website to avoid being a ‘spammer’.
Note — This is only for learning purposes. We do not encourage you to breach terms of any website.
See below on how to implement this method in just a few simple steps.
Proxies pool
Implementing a proxy server can be done easily in Python. A list of free proxies can be found here (Note that free proxies are usually less stable and slower than paid ones. If you don’t find the free ones good enough for your needs, you may consider getting a paid service).
Looking at the free proxies list, one can use BeautifulSoup in order to get the IP addresses and ports. The structure of the above-mentioned website can seen below.
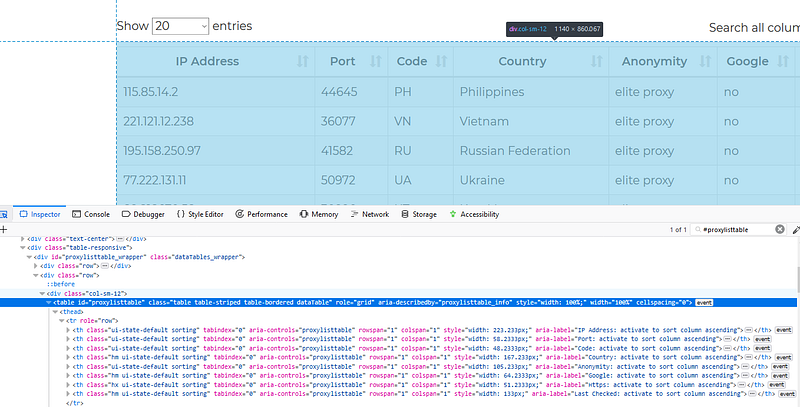
The following function retrieves all the proxies’ IPs and ports and returns a list of them:
Headers pool
There are many HTTP headers that can be passed as part of a request when using the requests package in Python. We passed two header elements (which were sufficient for us), namely the Accept header (user permissions) and user agent (Pseudo-Browser).
The pool of pseudo random headers was created as follows (see code below):
- Create a dictionary object of “accepts” where each accept header is related to a specific browser (depending on the user agent). A list of accept headers can be found here. This list contains default values for each user-agent and can be changed.
- Get a random user-agent using fake-useragent package in Python. This is super easy to use as seen in the code below. We suggest creating a list of user-agents beforehand just in case the fake-useragent is unavailable. An example of a user-agent:‘Mozilla/5.0 (Windows NT 6.2; rv:21.0) Gecko/20130326 Firefox/21.0’
- Create a dictionary object with accept and user-agent as keys and the corresponding values
The partial code (full function in the appendix below):
Using the headers and proxies pools
The following code shows an example of how to use the function we wrote before. We did not include the OOP code for the sake of simplicity. See Appendix for the full function random_header().
Summary
In this post we gave a brief introduction of web scraping, including when and why you should use it. We also spoke about more advanced web scraping techniques such as how to avoid being blocked by a website.
In our next posts we are going to talk about data enrichment using API calls.
A sneak peek of Part B — Using API calls to enrich your data:
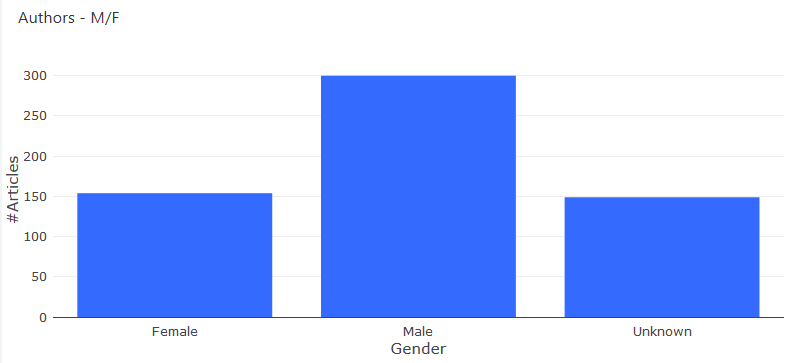
Gender distribution of the authors using the genderize API
Find us on Linkedin: Shai Ardazi, Eitan Kassuto

Presented by: Eitan Kassuto and Shai Ardazi, current Data Science Fellows of October 2018
Appendix
Future notes
- Consider using grequests for parallelizing the get requests. This can be done by doing the following:
This may not be as effective as it should be due to the limited speed of the free proxies but it is still worth trying.
- Using Selenium for handling Javascript elements.
Complete function — random_header
The full function to create random headers is as follows:
Note — In line 22 we saved a message into a logs file. It’s super important to have logs in your code! We suggest using logging package which is pretty simple to use.
Logging the flow
The logger class that we built and used everywhere in our code: